Project Title
Database Refactor and Upgrade of LibreHealth EHR
Mentors
Art Eaton and Terry Hill
PR
https://github.com/LibreHealthIO/LibreEHR/pull/599 (Under Review)
For other PRs
https://github.com/LibreHealthIO/LibreEHR/pulls/pri2si17-1997
Issue Opened
- https://github.com/LibreHealthIO/LibreEHR/issues/647
- https://github.com/LibreHealthIO/LibreEHR/issues/601
- https://github.com/LibreHealthIO/LibreEHR/issues/552
For other issues
https://github.com/LibreHealthIO/LibreEHR/issues/created_by/pri2si17-1997
Work Carried Out
This project is intended for refactoring of existing database for LibreHealth EHR application. It removes some of the tables which are not used in present application like icd9 codes related tables, documents related tables, etc. It also populates database with random data (as real as possible) which is used for testing database before actual run on real data. It can also be used while adding new feature before implementing that in main code base.
Old Schema v/s New Schema
There were flaws in old schema which is rectified in new one. Major improvements include:
- Lack of Relationship : In old schema, there is no proper relationship between tables and all the linking is maintained in code. In new schema, proper relationship is implemented between tables.
- Inappropriate Field Type : In old schema some fields were inappropriate, like integer is used in place of boolean, varchar is used in place of json type. This is taken care of in new schema.
- Lack of Normalization : Old schema lacked normalization, i.e., tables were not reduced to normal forms. This is taken care of in new schema and every table is broken to its lowest possible form and is properly linked.
- Lack of Comments : This may not be of much use as seen from technical perspective, but having table comment gives proper information of field and their purpose. This has been taken care of in new schema.
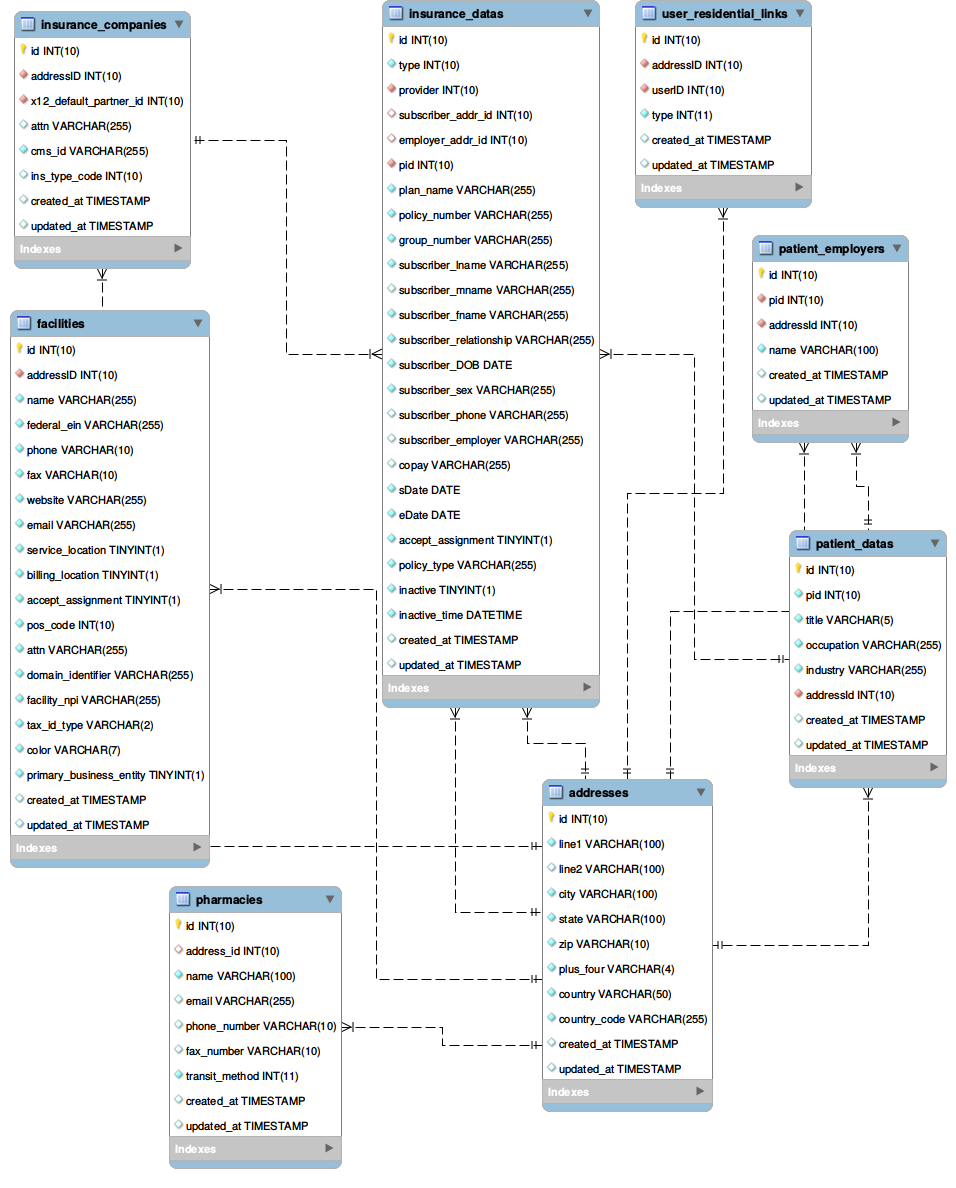
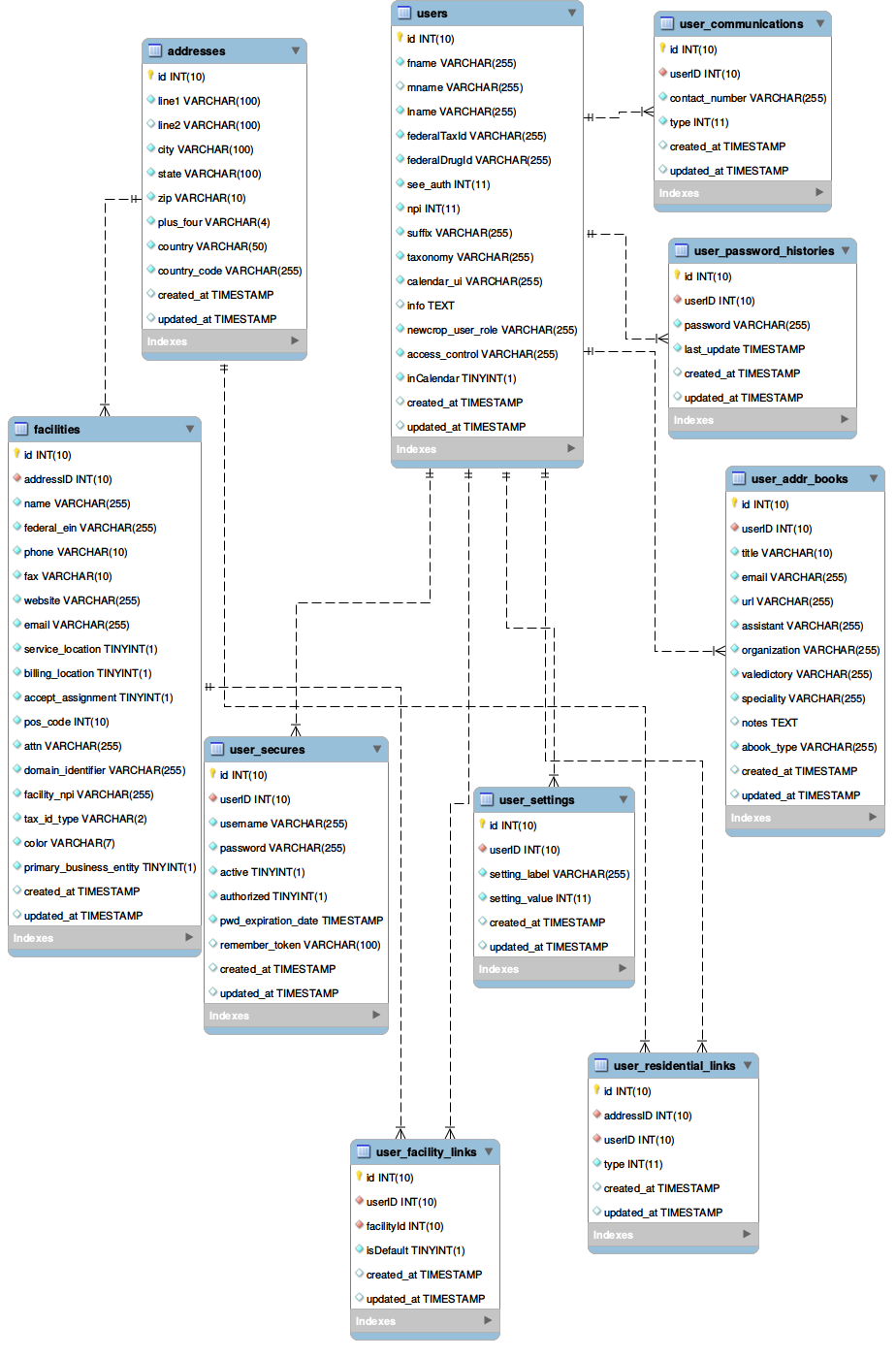
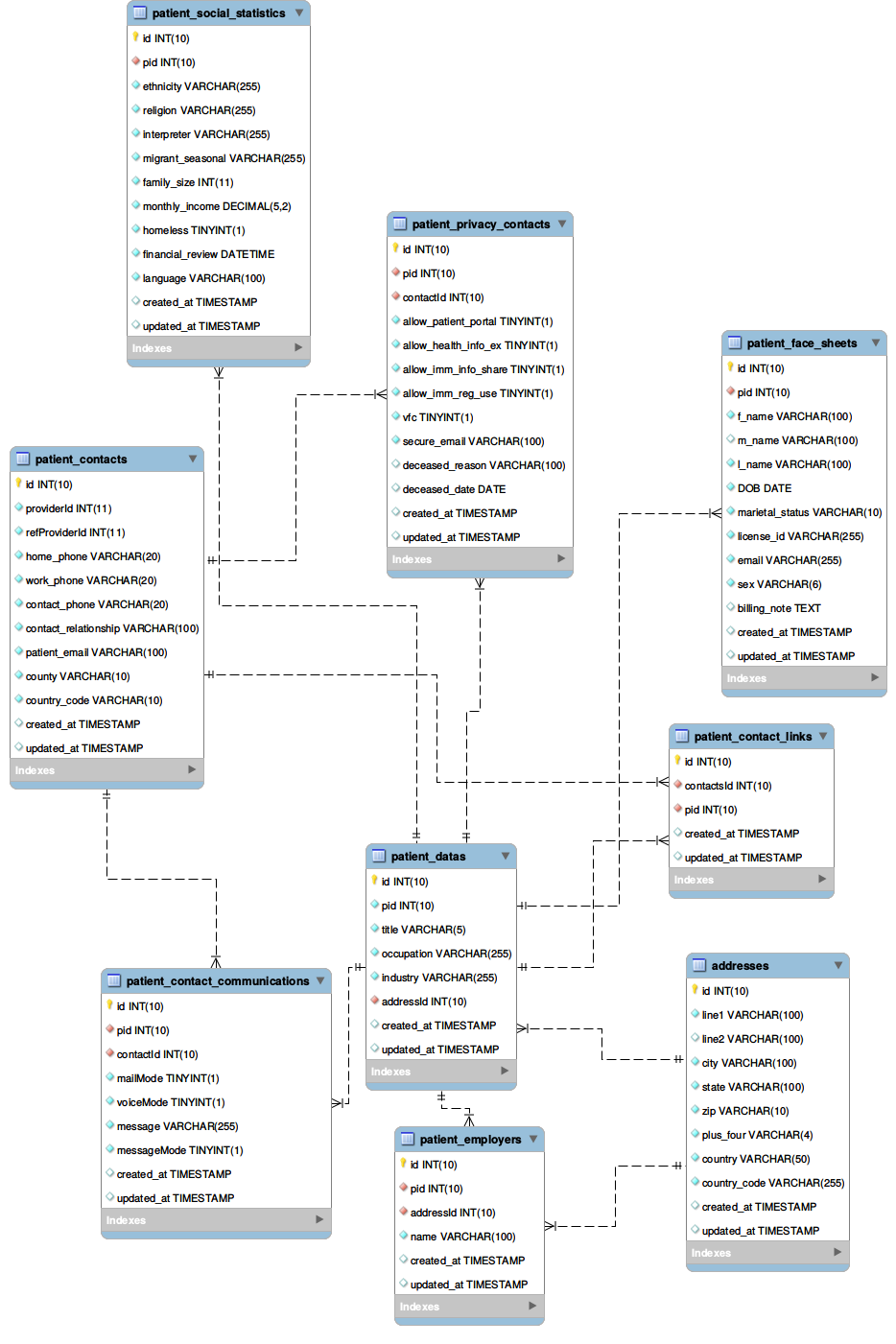
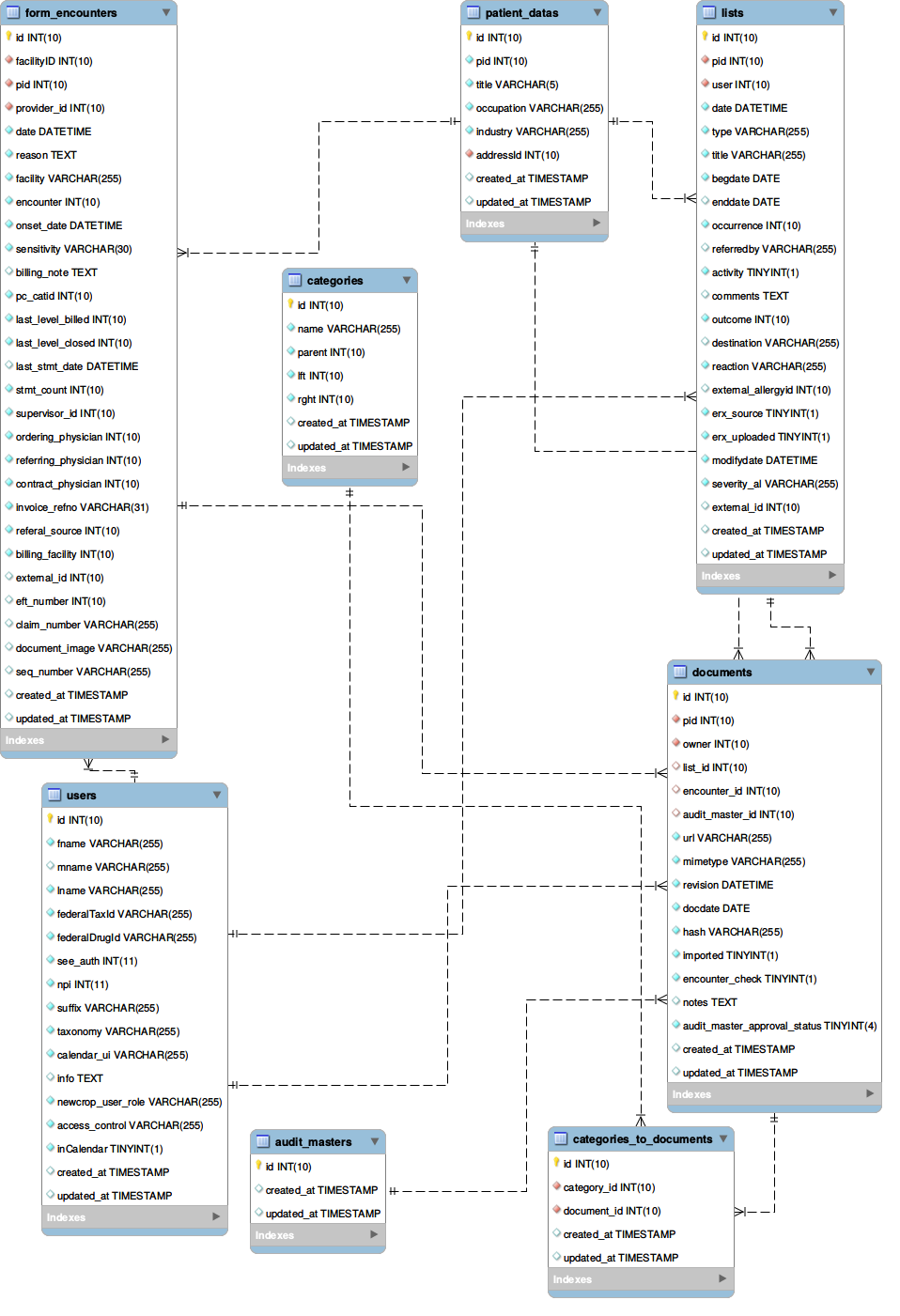
EER Diagram of important Modules
- Insurance
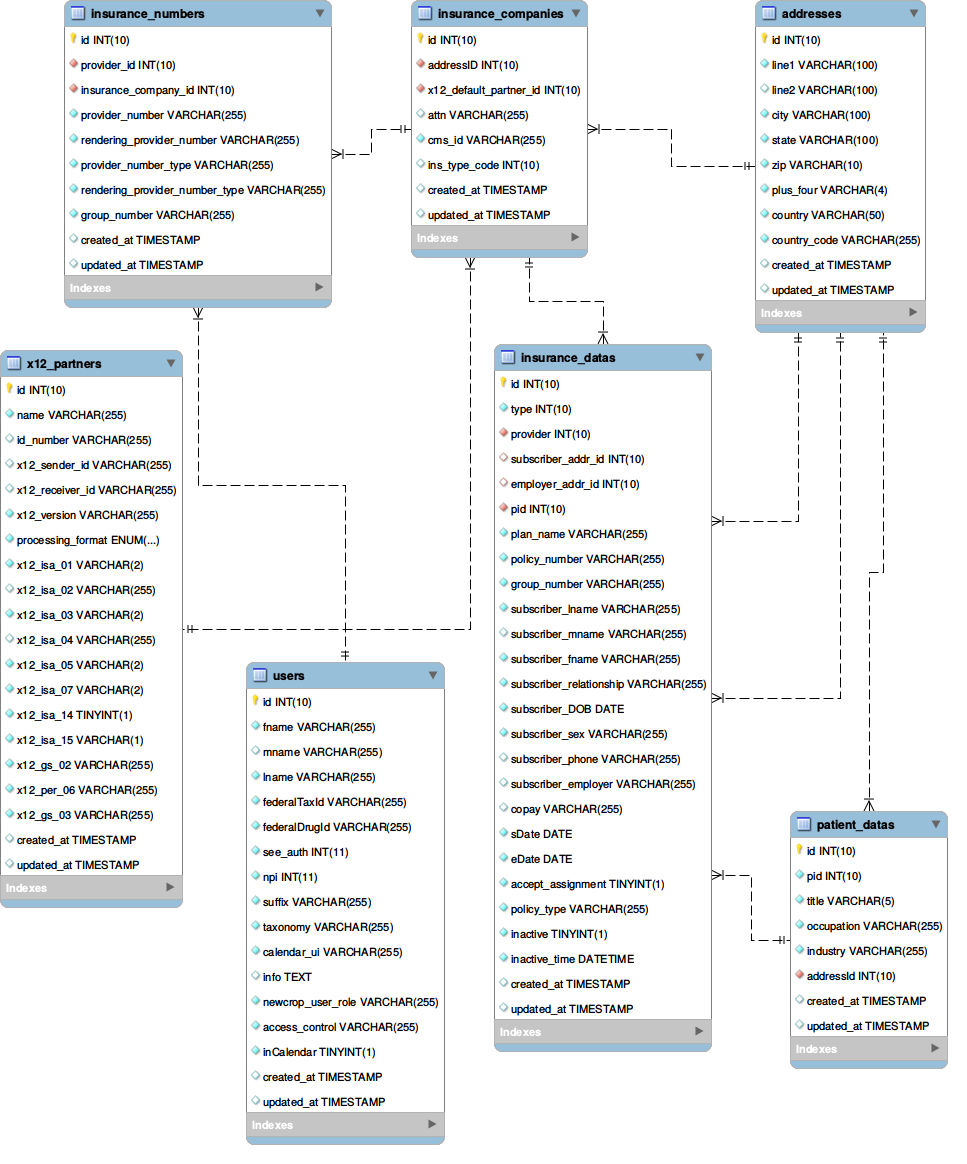
- Addresses
- Users
- Patients
- Drugs
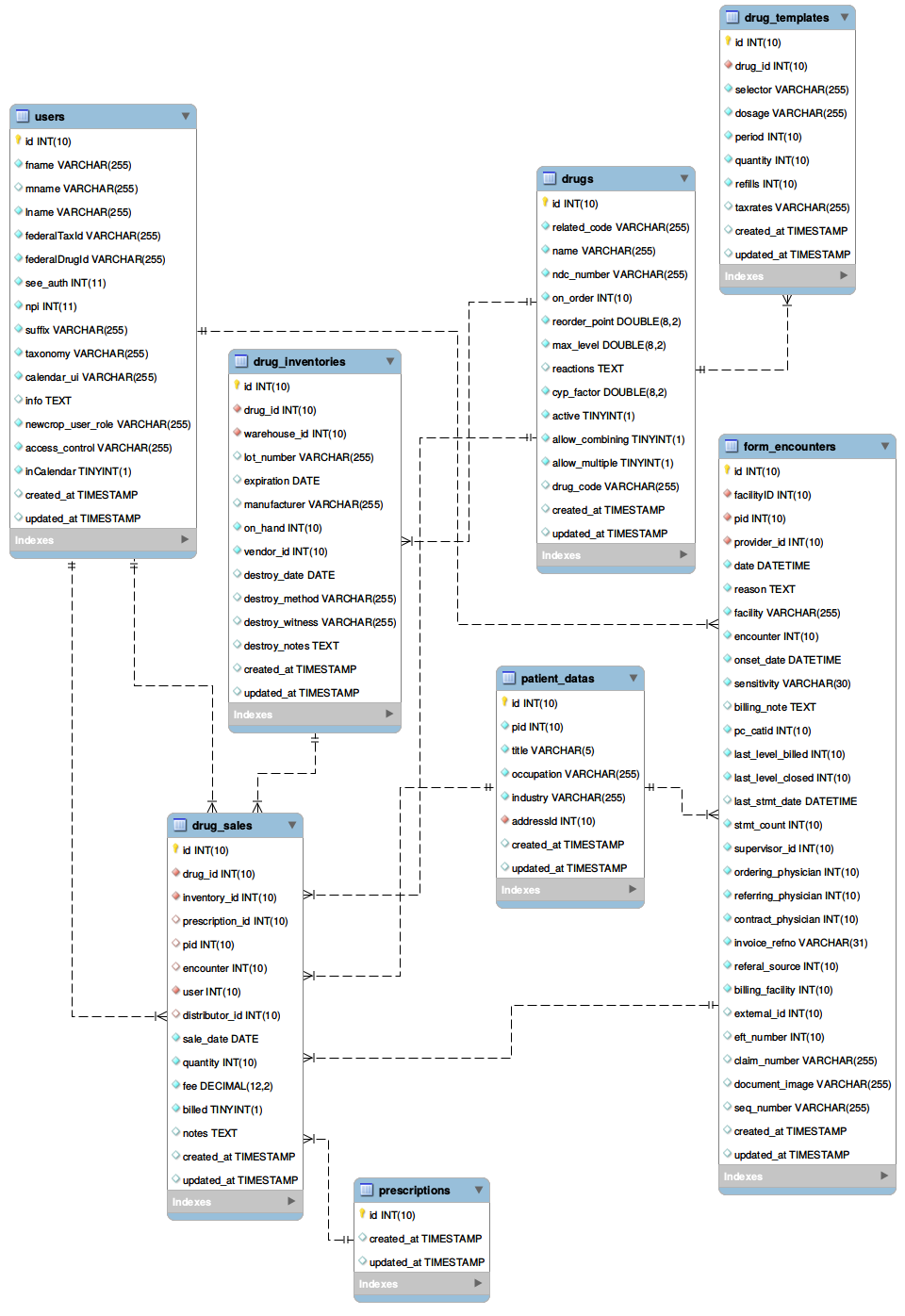
- Patient Documents
Seeding and Fake Data Generation
This part includes creation of random data for database. For more details on it, click here.
Future Work
Future work includes :
- Creation of migrations for remaining table after revamping of their UI.
- Creating models and integrate UI with it.
Acknowledgements
I would like to thank my mentors Art Eaton & Terry Hill for letting me do what I wanted and helping me wherever I got stuck, Tony McCormick although he was not my mentor, but he helped in all possible means and that’s the beauty of open source as all people work together and are there to help. Org admins Robert (Robby) O’Connor & Michel Downey for conducting it smoothly and all other members of this organization.

